Note: You can also watch my YouTube video tutorial where I configure Trusted Types on a live app.
XSS Defenses are Problematic
Throughout the last 20 years, cross-site scripting (XSS) attacks have consistently been one of the most common forms of vulnerability found in web applications.
Research performed in 2018 showed that about 18% of all reported vulnerabilities in web applications where some type of cross-site scripting attack.
In the early days of the web, common knowledge was to avoid XSS sinks while programming, don’t trust or render user input, and avoid the use of third-party scripts that could do the same. Unfortunately, many of these mitigation tips from the early days simply aren’t compatible with the data rich applications of today.
It could be said that XSS is the anti-thesis of a data rich web application. The more user provided inputs are incorporates into an application, the more likely it is for an XSS vulnerability to be found and exploited.
Content-Security-Policy (CSP) attempted to mitigate XSS by performing a blanket block on common sinks like eval() and inline script - disabling them in a secure by default manner. But the number of sinks in a modern web browser is so vast that managing all of them is an impossible task without sacrificing functionality.
Uncommon, but powerful XSS sinks like HTMLScriptElement.src, HTMLElement.manifest or Link.imagesrcset offer developers unique and potent mechanisms for creating and maintaining complex applications and state - but at the cost of additional XSS risk.
Third-party solutions for defending against XSS, like the industry-standard sanitizer DOMPurify exist - but are competing against the browser to offer a secure application context. That means when the browser updates, these tools too must update - and rapidly!
All in all, it could be concluded that XSS is simply a byproduct of the ever evolving web - the more complex web applications become - the more risk for user-provided input to be interpreted somehow as script.
Trusted types is a brand-new browser security feature that aims to eliminate some of these risks, while still giving the developer power to develop complex web applications.
Trusted Types Explained

“Trusted Types” is a security feature developed by the Google security team which is currently available on the latest versions of Chrome and Edge web browsers. For non-supported browsers, there is currently a polyfill which may be implemented that is maintained by w3c.
Trusted types is enabled in a webpage either by a new CSP header, or by adding a meta tag to the current webpage:
CSP Header Implementation
Content-Security-Policy: trusted-types;
Meta Tag Implementation
<meta http-equiv="Content-Security-Policy" content="require-trusted-types-for 'script'">
When trusted types is enabled, all XSS sinks known by the browser vendor should be disabled by default. This means that when a string is assigned to an XSS sink, it will throw a console error and halt script execution. The following JavaScript would no longer function:
const node = document.querySelector("#table-data");
const data = window.location.hash;
node.innerHTML = data; // Error: Failed to set the 'innerHTML' property on 'Element'...
The browser’s default mode has been changed thanks to Trusted Types from “accept-all” to “accept-none”.
Rather than configuring the browser to block specific XSS sinks (blocklist approach), we are now blocking all by default and the developer will be choosing which sinks to enable (allowlist approach).
Configuring Trusted Types
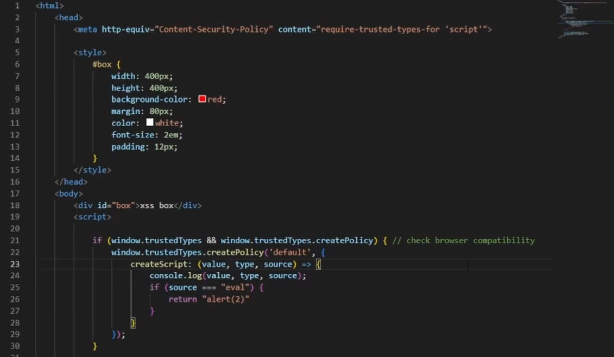
Now that Trusted Types is enabled, and blocking all known XSS sinks by default - we must enable and configure these sinks whenever we need to make use of their functionality.
Configuring trusted types is done via JavaScript code, similar to the following:
if (window.trustedTypes && trustedTypes.createPolicy) {
trustedTypes.createPolicy('sanitize-html', {
createHTML: string => DOMPurify.sanitize(string, {RETURN_TRUSTED_TYPE: true})
});
} else {
console.error("your browser does not yet support trusted types!")
}
First, we check to see if the browser supports trusted types - and log an error on the edge-case that the browser is Firefox or Safari (not yet supported).
Next, we create a policy. You may create as many trusted types policies as you would like, and each is capable of containing it’s own code dictating how a particular sink or set of sinks may be used in your application. This policy is named sanitize-html and allows sinks from the list of sinks that create HTML to be used - but only if they run their inputs through DOMPurify.sanitize() prior to injection.
This programming model might look similar to a rare, but potent design pattern called the proxy pattern in which an object intercepts data and acts on it prior to passing it on to the target function. This is because, trusted types in fact makes use of the Proxy object built into JavaScript in order to allow for such functionality to exist.
The Trusted Types spec bundles all known XSS sinks into one of three categories:
- createHTML: sinks that accept or generate HTML code
- createScript: sinks that accept or generate JavaScript
- createScriptURL: sinks that accept or generate URLs
You can reference any of these by name in a policy, in order to perform blanket sanitization on all sinks that fall within that category.
It’s also possible to operate on a single XSS sink, should you only wish to selectively enforce your policy:
trustedTypes.createPolicy('sanitize-jslinks', {
createScript: (value, type, sink) => {
if (sink === "javascript:") {
return 'void(0);' // return useless script
} else {
return value
}
}
})
Under the Hood
At a deeper level, Trusted Types works by defining three new interfaces:
interface TrustedHTML {
stringifier;
}
interface TrustedScriptURL {
stringifier;
}
interface TrustedScript {
stringifier;
}
The policies defined by the user as we saw above, determine what type of transformations occur against the values stored in these interfaces.
Upon loading an HTML page with Trusted Types enabled, the browser will cross-reference it’s list of XSS sinks and replace them with the best match of the three aforementioned interfaces.
For example, according to the spec element.innerHTML takes an input of type string denoted by the name htmlString which is than parsed into HTML nodes. When Trusted Types is enabled, element.innerHTML now takes an input of type TrustedHTML (a trusted type) which performs transformation as defined in a policy prior to insertion.
This is all documented in the official spec, despite being quite a bore to read:
- 3.3. Create a Trusted Type from literal
- 3.5. Get Trusted Type compliant string
- 3.6. Process value with a default policy
Summary

Trusted Types is a new browser security feature that enables your web applications to be secure by default when dealing with XSS sinks - the opposite of the way browsers have operated in the past.
With Trusted Types enabled, you (the developer) get to take control of what XSS sinks are available and what type of data they are able to accept.
Trusted Types is currently available on the latest versions of Chrome and Edge, or via official polyfill for other browsers.
]]>
 In July of 2004,
In July of 2004,  Later in 2010,
Later in 2010,